As the demand for efficient and powerful machine learning models grows, so does the need for methods that can compress these models without significantly sacrificing performance. The team at Hugging Face, known for their popular transformers library, has introduced a suite of distilled models referred to as Distil. This innovative approach to model compression has gathered attention for its ability to maintain high levels of accuracy while offering reduced model sizes and faster inference times. Let’s delve into the features and benefits of the Distil series and provide a review of the distillation research projects found on their GitHub repository.
What is Distil*?
Distil* represents a family of compressed models that began with DistilBERT. The concept is straightforward: take a large, pre-trained model and distil its knowledge into a smaller, more efficient version. DistilBERT, for example, is a compact adaptation of the original BERT model that has 40% fewer parameters yet retains 97% of BERT’s performance on the GLUE language understanding benchmark.
Features of Distil* Models
- Size and Speed: Distil* models are significantly smaller and faster than their counterparts. DistilBERT, for instance, offers a 60% improvement in speed over BERT-base.
- Performance: Despite the reduction in size, these models perform remarkably well. DistilBERT achieves 97% of BERT’s performance on the GLUE benchmark.
- Multi-Language Support: With DistilmBERT, there is support for 104 languages, making it a versatile option for various applications.
- Knowledge Distillation: The training process involves a technique called knowledge distillation, where the smaller model is trained to replicate the behavior of the larger model.
Benefits of Using Distil*
- Efficiency: The reduced size of Distil* models translates to lower memory requirements, making them ideal for environments with limited computational resources.
- Cost-Effectiveness: Faster inference times and smaller storage requirements can lead to significant cost savings, especially when deploying models at scale.
- Versatility: The range of Distil* models includes adaptations of BERT, RoBERTa, and GPT-2, providing a distilled version for different types of NLP tasks.
- Accessibility: By making powerful NLP models more accessible, Distil* facilitates the development of NLP applications even for those who might not have access to high-end hardware.
Review of Hugging Face’s Distillation on GitHub
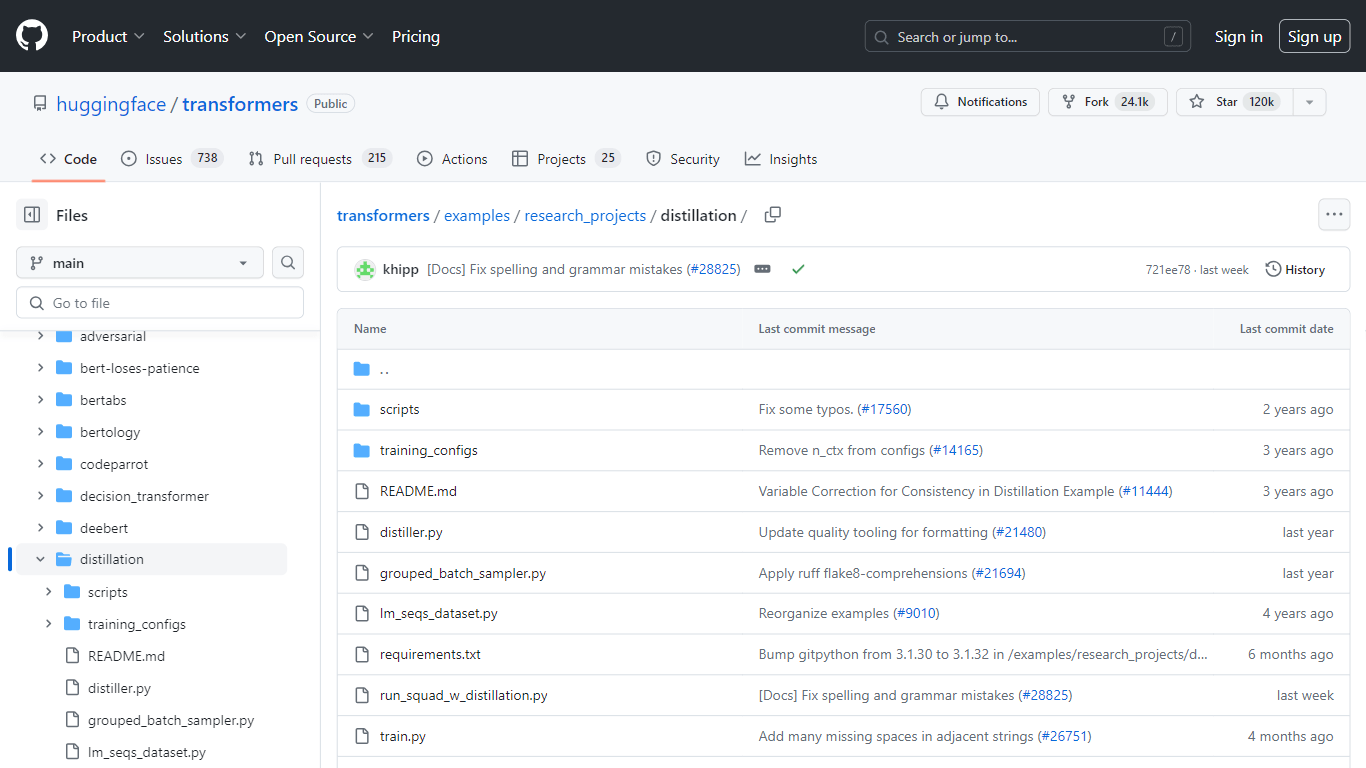
The GitHub repository for Hugging Face’s distillation projects serves as a comprehensive resource for understanding and utilizing these compressed models. It contains the original code used to train Distil* models, as well as examples showcasing how to use DistilBERT, DistilRoBERTa, and DistilGPT2.
Upon visiting the repository, users will find a neatly organized structure with directories for scripts, training configurations, and various Python files essential for the distillation process. The presence of a README.md file is particularly helpful, providing an overview of the updates, fixes, and methodological explanations behind the Distil* series.
Updates and Fixes
The Hugging Face team is active in maintaining the repository, with updates addressing bugs and performance issues. For example, they fixed a bug that caused the overestimation of metrics in their run_*.py scripts, ensuring more accurate performance reporting.
Documentation and Examples
The README.md file is a treasure trove of information, documenting the journey of the Distil* series from inception to its current state. It references the formal write-ups, the updates made over time, and the languages supported by the models. For newcomers, this is an invaluable guide to understanding the distillation process.
Code Quality and Usability
The code within the repository is well-documented and follows good programming practices, making it easier for others to replicate the training of Distil* models or adapt the code for their purposes. The inclusion of requirements in requirements.txt streamlines the setup process for developers interested in experimenting with the models.
Conclusion
The distillation research projects hosted by Hugging Face represent a significant advancement in the field of model compression. The Distil* series offers a practical solution for deploying efficient NLP models without compromising too much on performance. The GitHub repository not only provides the tools needed to work with these models but also a transparent view into the ongoing improvements and research in this area. Whether you are a researcher, a practitioner, or simply an enthusiast in the field of machine learning, the Distil* series and its accompanying repository are well worth exploring.